
Performance, accuracy, and flexibility
Our NC-SDK tool includes:
- Compilation & runtime for neural networks
- Heterogeneous compilation across CPU, GPU, and NNA
- Powerful quantisation tools for taking full advantage of your hardware
- Complete Netron-based UI for ease of use
The Netron-based interface brings together the full power of the Neural Compute SDK tools, making them easy and intuitive to use.
- View your models at multiple stages through the compilation process
- Full range of tool options at your fingertips: choose device partitioning or quantisation parameters manually, or let the tools do it automatically for you
- Understand execution of your models at runtime with PVRTune, our integrated performance visualiser
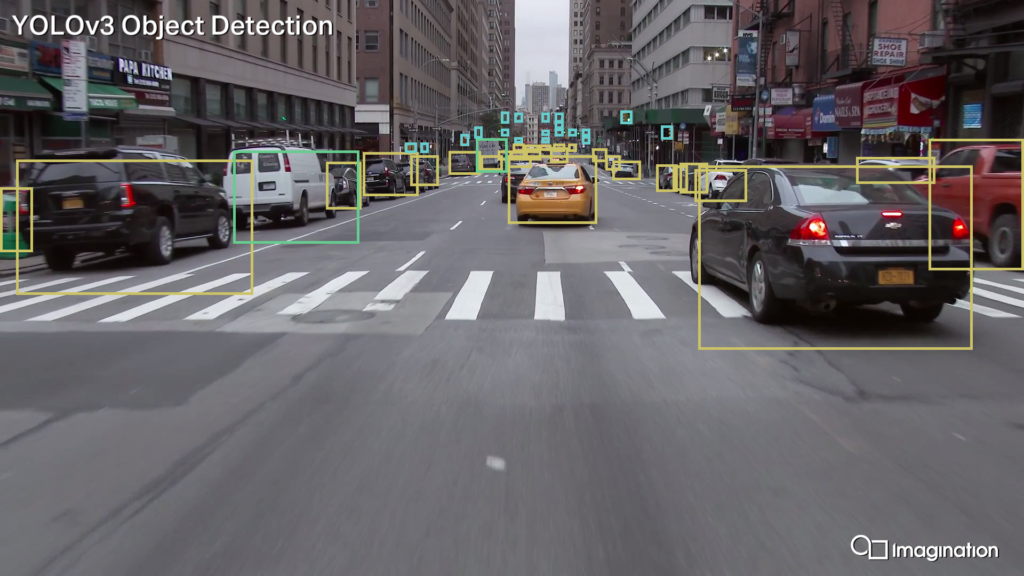
Take full advantage of all the hardware has to offer
The Neural Compute SDK makes it easy for you to deploy machine learning models efficiently across a range of devices.
IMGDNN
Neural network optimisation & runtime API for integrating into your application or framework.
TVM Heterogeneous Compilation
Handle multiple devices with ease. Compile models for a range of hardware with automatic partitioning to devices and efficient runtime synchronisation.
Quantisation Tools
Powerful tools to take full advantage of NNA and GPU hardware including state of the art quantisation and compression techniques.
Get started with our Neural Compute SDK
You can find more information on the Neural Compute SDK and download the academic version from our Imagination University Programme website.